May 11, 2026
CroncronA Unix-style scheduler for recurring commands. TelemHQ uses cron schedules to know when a tracker should receive its next ping.View glossary entrySource: AWS EventBridge Scheduler docs Monitoring Is Better When The Job Sends Data
Why I built TelemHQ to track what happened inside scheduled jobsscheduled jobA background task expected to run at predictable times. If it misses its expected window, TelemHQ can mark the tracker as failing.View glossary entrySource: AWS EventBridge Scheduler docs, not only whether they checked in.
The Basic Pattern
The pattern is intentionally small:
- Create a trackertrackerA monitored job, AI pipeline, worker, script, or automation in TelemHQ. Each tracker has its own ping URL and run history.View glossary entrySource: TelemHQ docs.
- Add a cron schedule if the job is supposed to run at a predictable time.
- Set a grace periodgrace periodExtra time after a job is expected to run before TelemHQ marks it late or failing. It keeps normal scheduling jitter from creating false alarms.View glossary entrySource: TelemHQ docs for late pingspingA request sent to TelemHQ after a job runs. A ping can be a simple heartbeat or include JSON payload data about what happened.View glossary entrySource: TelemHQ docs.
- Send one
POSTrequest after the job runs. - Include a JSONJSONA common text format for structured data. TelemHQ accepts JSON payloads so jobs can report fields like status, tokens, duration, and cost.View glossary entrySource: MDN glossary payloadpayloadThe structured data sent with a request. In TelemHQ, payloads should contain safe operational metadata, not prompts, completions, secrets, customer data, or private paths.View glossary entrySource: MDN API glossary with the fields you care about.
A plain heartbeatheartbeatA lightweight signal that proves a job checked in. TelemHQ extends heartbeats with payload data so the run can explain what happened.View glossary entrySource: TelemHQ docs still works:
curl -X POST "https://telemhq.com/ping/YOUR_TRACKING_TOKEN"
But the useful version looks more like this:
curl -X POST "https://telemhq.com/ping/YOUR_TRACKING_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"status": "success",
"duration_ms": 91000,
"records_processed": 12450,
"records_failed": 0,
"bytes_written": 8821044
}'
Now the tracker has more than a timestamp. It has a small run log.
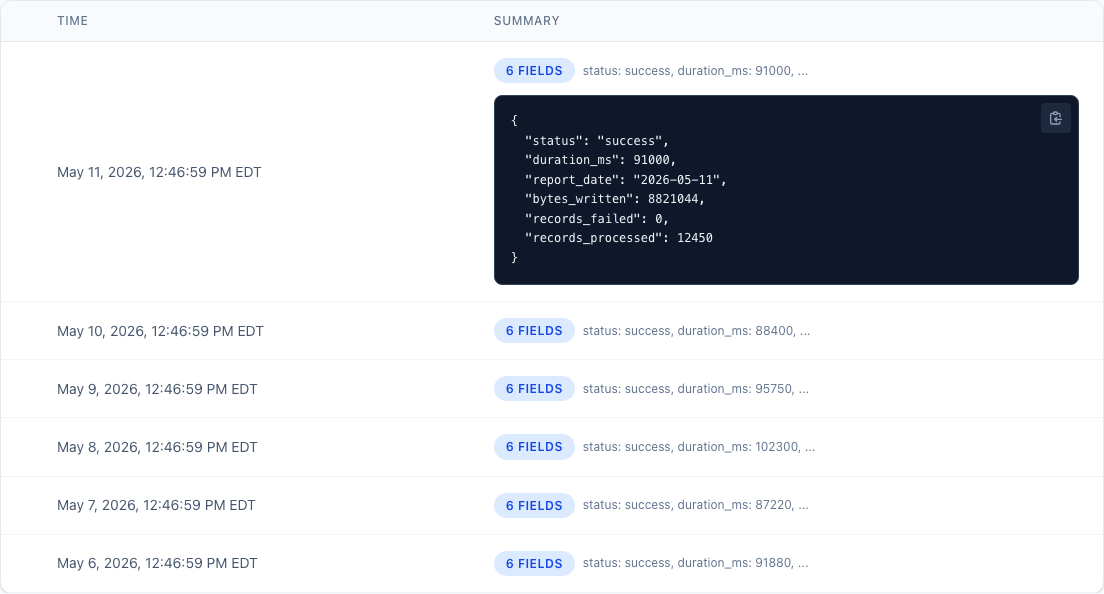
That is the difference between:
The nightly import ran.
And:
The nightly import ran in 91 seconds, processed 12,450 records, failed 0 records, and wrote 8.8 MB of output.
That second version is a lot easier to trust.
What I Would Put In The Payload
For a normal cron jobcron jobA scheduled task that runs automatically, often on a server. TelemHQ tracks cron jobs by receiving a ping after each run.View glossary entrySource: AWS EventBridge Scheduler docs, I would start with boring operational fields:
statusduration_msrecords_processedrecords_failedbytes_readbytes_writtenerror
For a scheduled report:
statusduration_msrows_generatedrecipientsemail_statusreport_date
For a backup:
statusduration_msbytes_writtenfile_countdestinationverification_status
For a scheduled AIAISoftware that performs tasks normally associated with human judgment, language understanding, or pattern matching. In TelemHQ, AI usually means jobs that call a model, agent, or coding tool.View glossary entrySource: Google Cloud Generative AI glossary job:
providermodelprojectstatusinput_tokensoutput_tokenstotal_tokenslatency_mscost_usditems_processeditems_failedeval_score
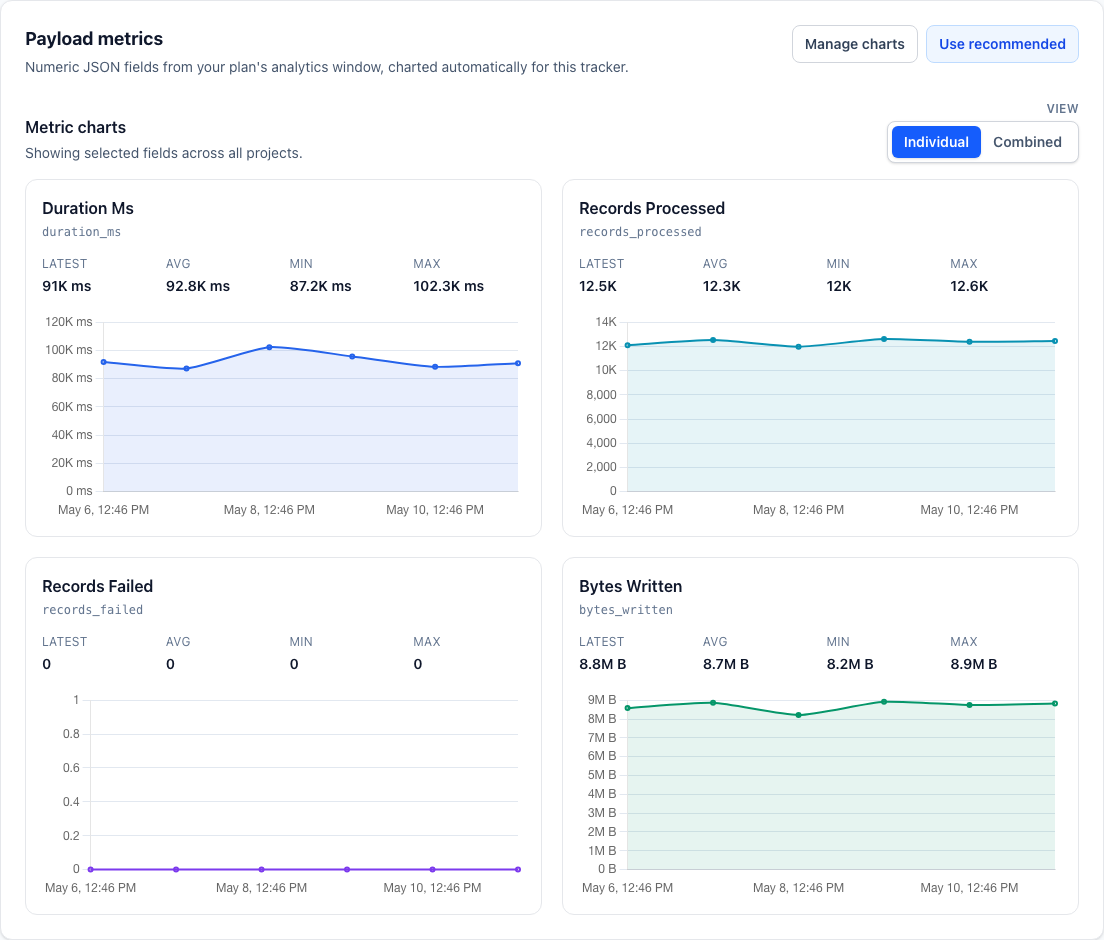
The specific fields do not matter as much as the habit: after every run, send the facts that would help you debug, explain, or trust that run later.
For most jobs, metadatametadataData about a run rather than the private content of the run itself, such as model name, duration, branch, item counts, or token totals.View glossary entrySource: MDN API glossary is enough. I would not send prompts, completions, generated code, secrets, customer data, or raw private paths unless there is a clear reason and everyone involved understands it.
The Sneaky Failure: Success With Bad Data
The most annoying failures are not always crashes.
Sometimes the script exits successfully, but the payload is bad:
records_processedis0records_failedis greater than0duration_msis much higher than normalcost_usdis above budgeteval_scoredrops below the threshold
That is why I like payload assertionsassertionA rule that checks payload data after a run. Assertions can flag a job as unhealthy even if the process technically completed.View glossary entrySource: TelemHQ docs.
For example, a tracker can treat these as rules:
status = successrecords_processed > 0records_failed = 0duration_ms < 300000
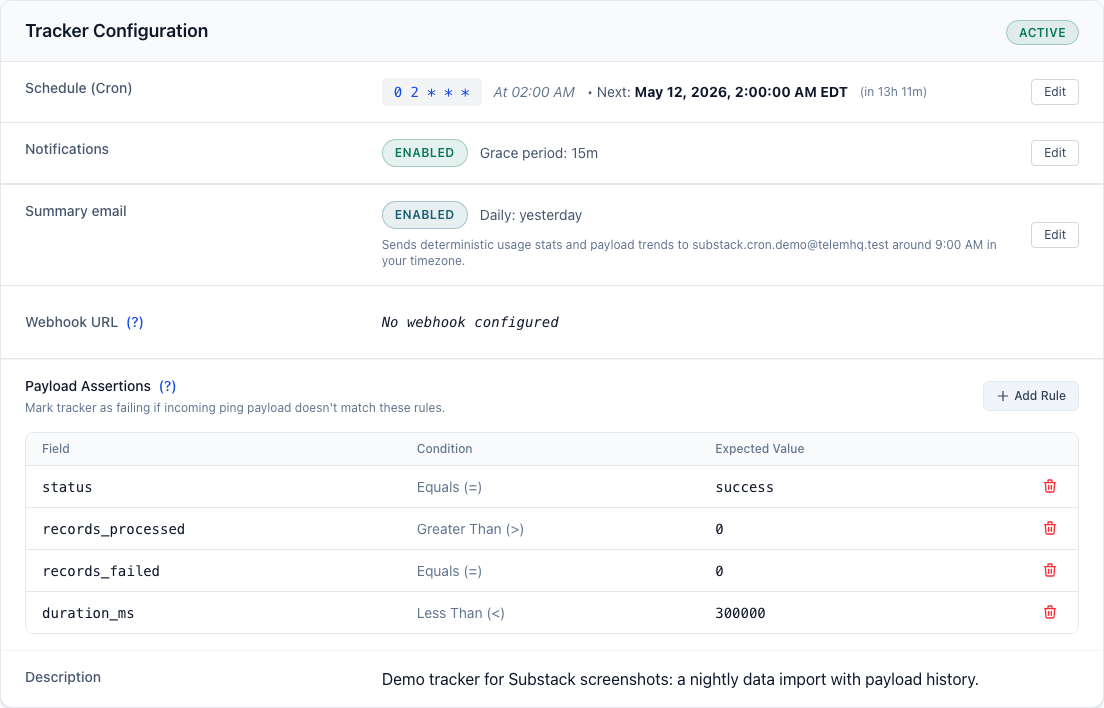
Now the job does not get a free pass because the process completed. The payload has to make sense too.
This is especially useful for AI and data jobs, where "completed" can hide bad output. A modelmodelThe AI system that processes input and returns output. For monitoring, the model name helps explain which tool or provider produced a run and how its token usage should be priced.View glossary entrySource: Anthropic model docs call can return something. A data sync can finish. An enrichment job can loop through the queue. But if the output count, failure count, quality score, or costcostThe money associated with a run, often estimated from token usage and provider pricing. TelemHQ can store cost fields when your job sends them.View glossary entrySource: OpenAI token guide is wrong, I want the monitoring system to know that.
Scheduled And Ad Hoc Jobsad hoc jobA task that runs whenever needed instead of on a fixed schedule. TelemHQ records each run but does not fail the tracker just because no scheduled ping arrived.View glossary entrySource: AWS EventBridge Scheduler docs Are Different
Some jobs run every five minutes or every night at 2 AM. Those should have a schedule. If they miss their expected check-in, the tracker should fail after the grace period.
Other jobs run whenever something happens: a webhookwebhookAn HTTP callback sent when an event happens. TelemHQ can use outgoing webhooks to notify another system about tracker events.View glossary entrySource: MDN API glossary fires, a queue receives work, a user clicks a button, or an agentagentAn AI application that uses a model, instructions, state, and tools to work toward a goal. Agents are useful to monitor because they can run for a while and make multiple tool calls.View glossary entrySource: Google Cloud Generative AI glossary starts a task. Those should not fail because they did not run on a clock.
In TelemHQ, that is why the schedule is optional.
If a tracker has a cron expressioncron expressionA compact schedule string made of time fields, such as minute, hour, day, month, and weekday. It describes when a recurring job should run.View glossary entrySource: AWS EventBridge Scheduler docs, it behaves like traditional cron monitoring: it expects pings on time.
If a tracker has no schedule, it behaves like run history for ad hoc work: it records every ping, stores the payload, and can still apply payload assertions, but it does not mark the tracker as failing because nothing happened today.
That distinction matters. A missed nightly report is a problem. A quiet queue might be perfectly fine.
Why This Became TelemHQ
This started with cron jobs, but the same problem shows up anywhere work runs in the background.
For classic cron jobs, I want to know:
- Did it run?
- Was it late?
- How long did it take?
- How much work did it do?
- Did anything fail?
For AI jobs, I also want to know:
- What provider and model ran?
- How many tokenstokensThe pieces of text an AI model processes. Token counts are often used to measure usage and calculate model cost.View glossary entrySource: OpenAI token guide did it use?
- What did it cost?
- Did it process the expected number of items?
- Did the payload pass quality or budget checks?
And for teams, I want the same pattern to roll up across projects, teammates, branchesbranchA line of development in Git. Tracking branch names helps connect AI coding usage or job cost to a specific task or change.View glossary entrySource: Git glossary, workersworkerA background process that performs work outside the main request path, such as syncing data, generating reports, or running AI tasks.View glossary entrySource: GitHub Actions CI docs, and model providers.
The integration does not need to be complicated. No SDKSDKA software development kit is a package of tools or libraries for building with a platform or API.View glossary entrySource: MDN API glossary is required. Any script that can make an HTTPHTTPThe web protocol used for requests and responses. TelemHQ ping URLs receive HTTP requests from jobs after they run.View glossary entrySource: MDN glossary request can send a useful ping.
A Small Upgrade To One Cron Job
If you have a cron job today, the smallest upgrade is this:
- Add a tracker for the job.
- Paste the ping URL into the script.
- Send a
POSTat the end of the run. - Add one or two payload fields that prove the job did useful work.
For example:
await fetch(process.env.TELEMHQ_PING_URL, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
status: "success",
duration_ms: durationMs,
records_processed: recordsProcessed,
records_failed: recordsFailed
})
});
That is enough to start building a real history: not only that the job ran, but what it did.
I am building TelemHQ for this exact kind of work: scheduled jobs, ad hoc AI workers, AI coding tools like CodexCodexAn AI coding assistant workflow. TelemHQ can record Codex usage by branch, task, model, token counts, cost, and run result.View glossary entrySource: OpenAI token guide and Claude CodeClaude CodeA Claude-based coding tool. In TelemHQ, its usage can be tracked like other coding assistants when a run sends structured metadata after work completes.View glossary entrySource: Anthropic model docs, model usage across OpenAIOpenAIAn AI provider whose APIs and models are commonly used for text generation, coding, reasoning, embeddings, and agent workflows.View glossary entrySource: OpenAI token guide, AnthropicAnthropicThe company behind Claude, a family of AI models used for chat, coding, analysis, and tool-using workflows.View glossary entrySource: Anthropic model docs, GeminiGeminiGoogle’s family of multimodal AI models. TelemHQ treats Gemini runs like other model runs when they send comparable payload fields.View glossary entrySource: Google Cloud LLM overview, LlamaLlamaA family of AI models often used through hosted APIs or local inference. TelemHQ can track Llama jobs when the run reports model and usage metadata.View glossary entrySource: Meta Llama docs, QwenQwenA family of open foundation models from Alibaba Cloud’s Qwen team, used for language, coding, and multimodal AI workflows.View glossary entrySource: Qwen model site, DeepSeekDeepSeekAn AI model provider with an API that supports OpenAI-compatible and Anthropic-compatible usage patterns for model calls.View glossary entrySource: DeepSeek API docs, KimiKimiAn AI assistant and model platform from Moonshot AI, with model APIs that can be monitored when jobs report model, token, and run metadata.View glossary entrySource: Kimi API Platform, and GLMGLMA family of large models from Z.ai, formerly known internationally through Zhipu AI, used for coding, agent, and general AI workflows.View glossary entrySource: Z.ai, RAG syncsRAGRetrieval-augmented generation improves model output by retrieving relevant information from a knowledge source and grounding the response in that context.View glossary entrySource: Google Cloud Generative AI glossary, evalsevalA test or scoring run used to judge whether an AI system behaved well enough. TelemHQ can track eval score, pass rate, failures, and regressions.View glossary entrySource: Google Cloud Generative AI glossary, agents, and traditional cron jobs that need more than "it ran."
The useful pattern is simple: send one POSTPOSTAn HTTP method used to send data to a server. TelemHQ pings use POST when a job reports a run and optional payload.View glossary entrySource: MDN HTTP docs after the run, include the payload fields that matter, and keep the history somewhere your future self or team can actually inspect.