May 25, 2026
How Teams Can Track AI Usage In One Place
The useful part is not surveillance. It is agreeing on a small set of fields so scattered AI work can be understood later.
Read postTelemHQ Blog
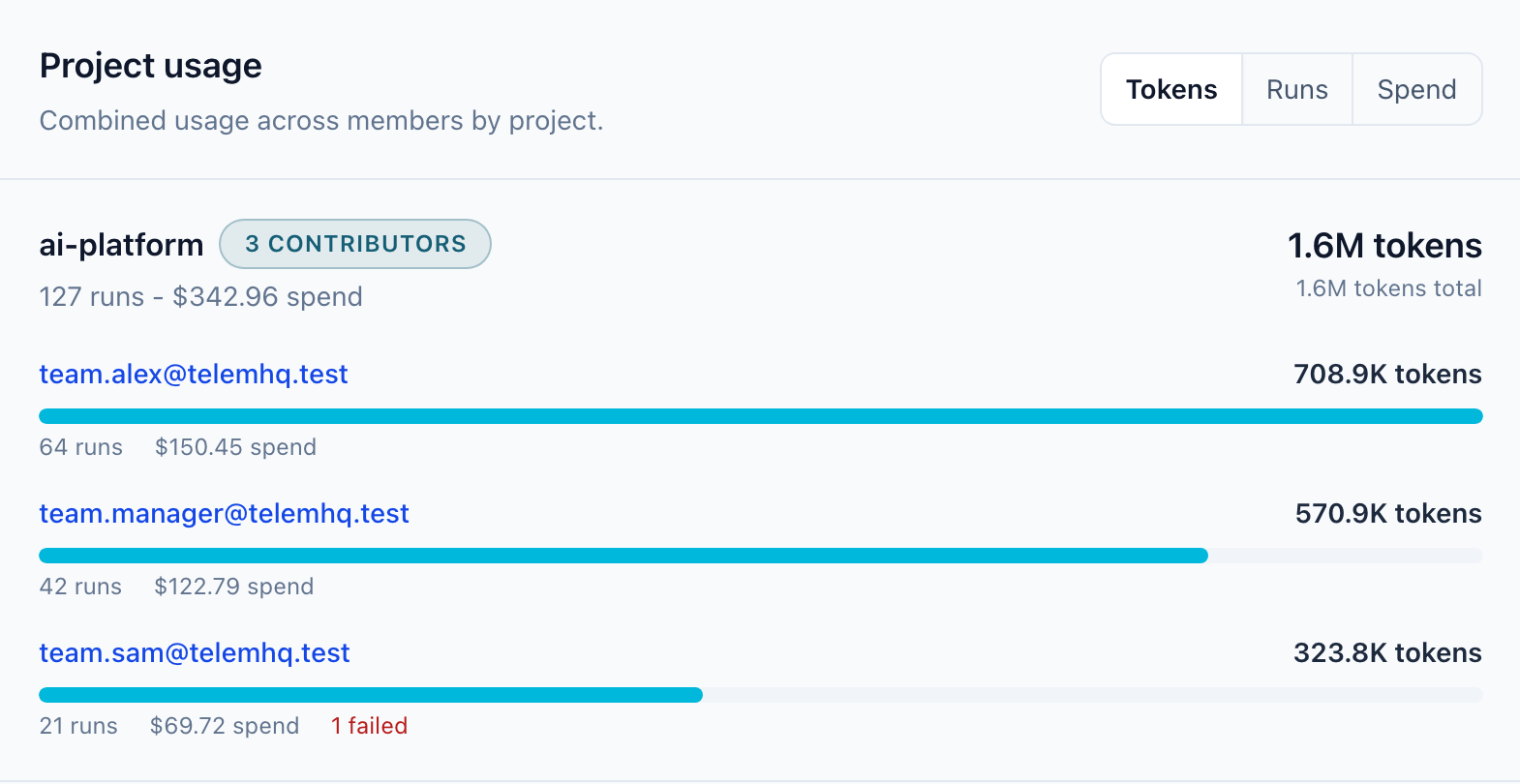
Founder-led posts about monitoring scheduled jobsscheduled jobA background task expected to run at predictable times. If it misses its expected window, TelemHQ can mark the tracker as failing.View glossary entrySource: AWS EventBridge Scheduler docs, ad hocad hoc jobA task that runs whenever needed instead of on a fixed schedule. TelemHQ records each run but does not fail the tracker just because no scheduled ping arrived.View glossary entrySource: AWS EventBridge Scheduler docs AI workersworkerA background process that performs work outside the main request path, such as syncing data, generating reports, or running AI tasks.View glossary entrySource: GitHub Actions CI docs, coding tools, token usagetokensThe pieces of text an AI model processes. Token counts are often used to measure usage and calculate model cost.View glossary entrySource: OpenAI token guide, RAG syncsRAGRetrieval-augmented generation improves model output by retrieving relevant information from a knowledge source and grounding the response in that context.View glossary entrySource: Google Cloud Generative AI glossary, evalsevalA test or scoring run used to judge whether an AI system behaved well enough. TelemHQ can track eval score, pass rate, failures, and regressions.View glossary entrySource: Google Cloud Generative AI glossary, agentsagentAn AI application that uses a model, instructions, state, and tools to work toward a goal. Agents are useful to monitor because they can run for a while and make multiple tool calls.View glossary entrySource: Google Cloud Generative AI glossary, and the payload fields that make background work easier to trust.
May 25, 2026
The useful part is not surveillance. It is agreeing on a small set of fields so scattered AI work can be understood later.
Read post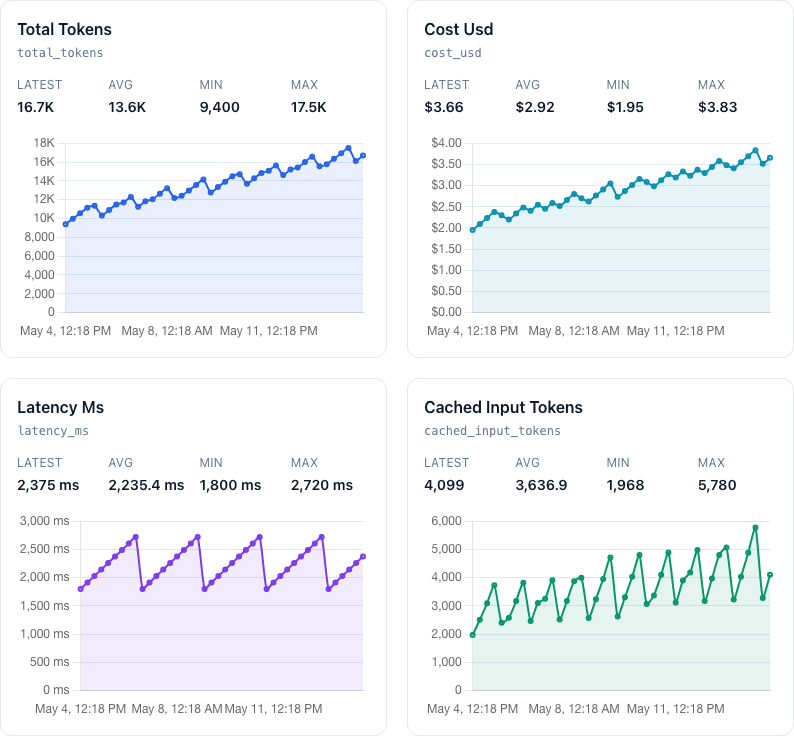
May 18, 2026
A practical metadatametadataData about a run rather than the private content of the run itself, such as model name, duration, branch, item counts, or token totals.View glossary entrySource: MDN API glossary shape for tracking modelmodelThe AI system that processes input and returns output. For monitoring, the model name helps explain which tool or provider produced a run and how its token usage should be priced.View glossary entrySource: Anthropic model docs, token, costcostThe money associated with a run, often estimated from token usage and provider pricing. TelemHQ can store cost fields when your job sends them.View glossary entrySource: OpenAI token guide, latencylatencyHow long a request or job takes to respond. AI job latency helps teams spot slow model calls, overloaded workers, or expensive retries.View glossary entrySource: MDN glossary, and job results across OpenAIOpenAIAn AI provider whose APIs and models are commonly used for text generation, coding, reasoning, embeddings, and agent workflows.View glossary entrySource: OpenAI token guide, ClaudeClaudeAnthropic’s family of AI models. TelemHQ can track Claude jobs by recording model names, token usage, latency, cost, and run metadata.View glossary entrySource: Anthropic model docs, CodexCodexAn AI coding assistant workflow. TelemHQ can record Codex usage by branch, task, model, token counts, cost, and run result.View glossary entrySource: OpenAI token guide, and other AI tools.
Read post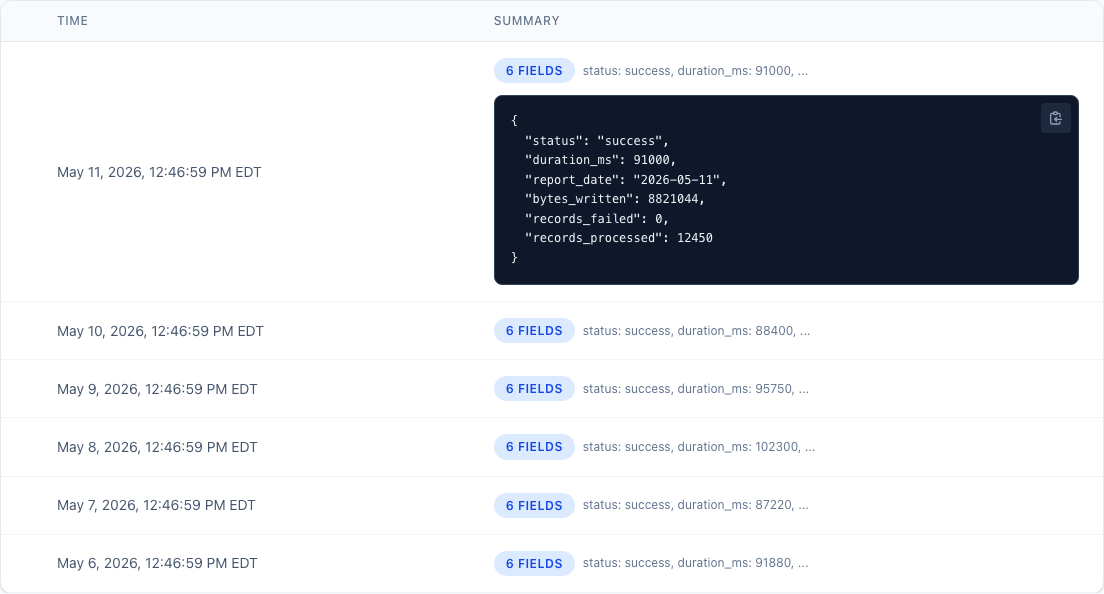
May 11, 2026
Why I built TelemHQ to track what happened inside scheduled jobs, not only whether they checked in.
Read post