May 18, 2026
One PayloadpayloadThe structured data sent with a request. In TelemHQ, payloads should contain safe operational metadata, not prompts, completions, secrets, customer data, or private paths.View glossary entrySource: MDN API glossary Format For OpenAIOpenAIAn AI provider whose APIs and models are commonly used for text generation, coding, reasoning, embeddings, and agent workflows.View glossary entrySource: OpenAI token guide, ClaudeClaudeAnthropic’s family of AI models. TelemHQ can track Claude jobs by recording model names, token usage, latency, cost, and run metadata.View glossary entrySource: Anthropic model docs, CodexCodexAn AI coding assistant workflow. TelemHQ can record Codex usage by branch, task, model, token counts, cost, and run result.View glossary entrySource: OpenAI token guide, And Other AIAISoftware that performs tasks normally associated with human judgment, language understanding, or pattern matching. In TelemHQ, AI usually means jobs that call a model, agent, or coding tool.View glossary entrySource: Google Cloud Generative AI glossary Jobs
A practical metadatametadataData about a run rather than the private content of the run itself, such as model name, duration, branch, item counts, or token totals.View glossary entrySource: MDN API glossary shape for tracking modelmodelThe AI system that processes input and returns output. For monitoring, the model name helps explain which tool or provider produced a run and how its token usage should be priced.View glossary entrySource: Anthropic model docs, tokentokensThe pieces of text an AI model processes. Token counts are often used to measure usage and calculate model cost.View glossary entrySource: OpenAI token guide, costcostThe money associated with a run, often estimated from token usage and provider pricing. TelemHQ can store cost fields when your job sends them.View glossary entrySource: OpenAI token guide, latencylatencyHow long a request or job takes to respond. AI job latency helps teams spot slow model calls, overloaded workers, or expensive retries.View glossary entrySource: MDN glossary, and job results across OpenAI, Claude, Codex, and other AI tools.
The Shape Matters More Than The Provider
A provider-neutral AI job payload is a small JSONJSONA common text format for structured data. TelemHQ accepts JSON payloads so jobs can report fields like status, tokens, duration, and cost.View glossary entrySource: MDN glossary object that records the same run metadata across different tools: provider, model, project, status, token usage, latency, cost, and job results.
The provider matters. The model matters. But the monitoring fields are usually the same.
For most AI jobs, I would start with this common set:
providermodelprojectstatusinput_tokensoutput_tokenscached_input_tokensreasoning_tokenstotal_tokenslatency_msorduration_mscost_usditems_processeditems_failedeval_score
You will not have every field for every job. That is fine.
For cost_usd, use your own pricing calculation, provider usage APIAPIA software interface that lets programs interact through defined rules, URLs, methods, and data formats.View glossary entrySource: MDN API glossary, or billing export. Model prices and aliases change, so I treat this field as an estimate that should be explainable later.
An eval runevalA test or scoring run used to judge whether an AI system behaved well enough. TelemHQ can track eval score, pass rate, failures, and regressions.View glossary entrySource: Google Cloud Generative AI glossary might send eval_score, test_cases, and failed_cases. A RAG syncRAGRetrieval-augmented generation improves model output by retrieving relevant information from a knowledge source and grounding the response in that context.View glossary entrySource: Google Cloud Generative AI glossary might send documents_indexed, chunks_created, and embedding_model. A coding agentagentAn AI application that uses a model, instructions, state, and tools to work toward a goal. Agents are useful to monitor because they can run for a while and make multiple tool calls.View glossary entrySource: Google Cloud Generative AI glossary might send git_repo, git_branch, issue_id, and token counts.
The point is to keep the shared fields boring and consistent. If every job calls the model field model, the project field project, and the cost field cost_usd, the historyrun historyThe stored record of previous job runs. TelemHQ uses run history to show payloads, failures, timing, token totals, and trends over time.View glossary entrySource: TelemHQ docs becomes easier to search, group, chart, and explain later.
| Field group | Example fields | What it helps answer |
|---|---|---|
| Identity | provider, model, project |
What ran, and where does it belong? |
| Usage | input_tokens, output_tokens, total_tokens |
How much model work happened? |
| Operations | status, latency_ms, items_failed |
Did the run finish cleanly and on time? |
| Cost and quality | cost_usd, eval_score |
Was the run worth trusting or investigating? |
The Same Payload Shape For OpenAI And Claude
Here is an example OpenAI job:
{
"provider": "openai",
"model": "gpt-5.2",
"project": "support-summary",
"status": "success",
"input_tokens": 4200,
"output_tokens": 640,
"cached_input_tokens": 900,
"reasoning_tokens": 0,
"total_tokens": 4840,
"latency_ms": 2300,
"cost_usd": 0.02,
"items_processed": 128,
"items_failed": 0
}
And here is a Claude job using the same shape:
{
"provider": "anthropic",
"model": "claude-3-5-haiku-20241022",
"project": "support-summary",
"status": "success",
"input_tokens": 3900,
"output_tokens": 710,
"cached_input_tokens": 0,
"reasoning_tokens": 0,
"total_tokens": 4610,
"latency_ms": 2600,
"cost_usd": 0.01,
"items_processed": 128,
"items_failed": 0
}
Those examples are not trying to hide provider differences. OpenAI, AnthropicAnthropicThe company behind Claude, a family of AI models used for chat, coding, analysis, and tool-using workflows.View glossary entrySource: Anthropic model docs, local models, coding tools, batchbatchA group of records or tasks processed together. Batch jobs are often monitored by counting processed items, failed items, duration, and cost.View glossary entrySource: Anthropic API overview APIs, and hosted agents will all expose usage in their own way.
I would use stable model IDs in production when the provider recommends them. Aliases are handy while testing, but stable IDs make old runs easier to explain later.
But once your job has the numbers, the monitoring payload can normalize the parts you care about:
- who ran the job
- what project it belongs to
- which provider and model ran
- how many tokens it used
- how long it took
- what it cost
- how much work it completed
- whether it failed in a way the process exit code did not catch
That common shape is what makes mixed-model usage readable.
The One-POSTPOSTAn HTTP method used to send data to a server. TelemHQ pings use POST when a job reports a run and optional payload.View glossary entrySource: MDN HTTP docs Pattern
The integration can stay small.
At the end of a job, send a POST to the trackertrackerA monitored job, AI pipeline, worker, script, or automation in TelemHQ. Each tracker has its own ping URL and run history.View glossary entrySource: TelemHQ docs URL:
curl -X POST "https://telemhq.com/ping/YOUR_TRACKING_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"provider": "openai",
"model": "gpt-5.2",
"project": "support-summary",
"status": "success",
"input_tokens": 4200,
"output_tokens": 640,
"total_tokens": 4840,
"latency_ms": 2300,
"cost_usd": 0.02,
"items_processed": 128,
"items_failed": 0
}'
That request gives the run a timestamp and a payload.
If the tracker has a schedule, TelemHQ can also care whether the job checked in on time. If the tracker is ad hocad hoc jobA task that runs whenever needed instead of on a fixed schedule. TelemHQ records each run but does not fail the tracker just because no scheduled ping arrived.View glossary entrySource: AWS EventBridge Scheduler docs, it can behave more like run history for workersworkerA background process that performs work outside the main request path, such as syncing data, generating reports, or running AI tasks.View glossary entrySource: GitHub Actions CI docs, agents, and manually triggered tasks.
Either way, the payload is the important part. It turns "the job ran" into "the job used this model, spent this much, processed this many items, and finished with this status."
Numeric Fields Become The Start Of A Dashboard
The nice thing about a JSON payload is that the numbers already have names.
If a run sends:
total_tokenslatency_mscost_usditems_processeditems_failedeval_score
those fields are useful over time. You can chart them, compare them between jobs, and notice when one value changes.
Here is what that looks like in TelemHQ when an AI usage tracker sends the same numeric fields over time:
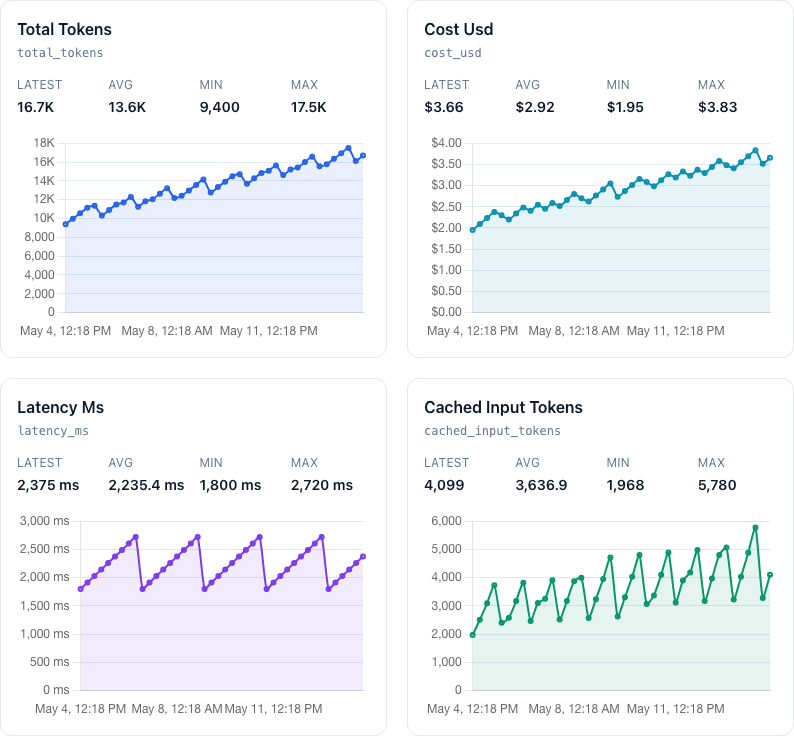
That is why I like sending small, boring numeric fields instead of storing a blob of logs. Logs are still useful when you need detail. But for monitoring, I want the values that can answer questions quickly:
- Did token usage climb after a prompt change?
- Did latency jump when we switched providers?
- Did the job process fewer items than normal?
- Did failed items start showing up after a deploy?
- Did cost increase on one project while the others stayed flat?
This Works Beyond Provider APIs
Provider-neutral payloads are not only for direct API calls.
A Codex usage tracker might send:
{
"tool": "codex",
"provider": "openai",
"model": "gpt-5.2-codex",
"project": "billing-api",
"git_repo": "company/billing-api",
"git_branch": "issue-482-refactor-invoices",
"issue_id": "482",
"status": "completed",
"input_tokens": 118000,
"output_tokens": 9200,
"cached_input_tokens": 51000,
"reasoning_tokens": 14000,
"total_tokens": 127200,
"cost_usd": 0.45
}
A RAG indexing job might send:
{
"provider": "openai",
"model": "text-embedding-3-large",
"project": "docs-search",
"status": "success",
"documents_scanned": 940,
"documents_indexed": 936,
"chunks_created": 12840,
"items_failed": 4,
"duration_ms": 184000,
"total_tokens": 221000,
"cost_usd": 0.03
}
An eval run might send:
{
"provider": "anthropic",
"model": "claude-3-5-haiku-20241022",
"project": "support-summary",
"status": "success",
"test_cases": 200,
"failed_cases": 14,
"pass_rate": 0.93,
"eval_score": 0.88,
"duration_ms": 64000,
"cost_usd": 0.42
}
The extra fields can vary by job. The shared fields keep the history connected.
That means a team can look across direct model calls, AI coding tools, RAG syncs, evals, queue workers, and scheduled scripts without forcing every workflow into a different monitoring setup.
Do Not Send The Whole Job
There is a privacy habit I want to be explicit about:
For monitoring, metadata is usually enough.
I would not send prompts, completions, generated code, retrieved documents, customer data, secrets, API keys, full file contents, or raw private paths as payload data. Most monitoring questions can be answered with counts, IDs, status fields, model names, token usage, cost, latency, and project metadata.
For example, this is useful:
{
"project": "support-summary",
"provider": "openai",
"model": "gpt-5.2",
"status": "success",
"tickets_processed": 128,
"tickets_failed": 0,
"total_tokens": 4840,
"cost_usd": 0.02
}
This is the line I would try not to cross by default:
{
"prompt": "Full private prompt text goes here",
"completion": "Full generated response goes here",
"customer_email": "person@example.com",
"local_path": "/private/company/customer-export.csv"
}
The first payload helps you understand the run. The second payload creates a data handling problem you probably did not need.
A Small Starting Point
If you are tracking AI work across more than one provider or tool, I would start with one tracker and two jobs.
Send the same core fields from both:
providermodelprojectstatusinput_tokensoutput_tokenstotal_tokenslatency_msorduration_mscost_usd
Then add the fields that prove the job did useful work:
items_processeditems_failedeval_scoredocuments_indexedchunks_createdgit_branchissue_id
That is enough to see the shape of your AI usage in one place.
If you want a provider-specific starting point, I keep setup guides for OpenAI pipeline tracking, Claude pipeline tracking, and Codex usage tracking.
I am building TelemHQ for this exact kind of work: scheduled jobsscheduled jobA background task expected to run at predictable times. If it misses its expected window, TelemHQ can mark the tracker as failing.View glossary entrySource: AWS EventBridge Scheduler docs, ad hoc AI workers, AI coding tools like Codex and Claude CodeClaude CodeA Claude-based coding tool. In TelemHQ, its usage can be tracked like other coding assistants when a run sends structured metadata after work completes.View glossary entrySource: Anthropic model docs, model usage across OpenAI, Anthropic, GeminiGeminiGoogle’s family of multimodal AI models. TelemHQ treats Gemini runs like other model runs when they send comparable payload fields.View glossary entrySource: Google Cloud LLM overview, LlamaLlamaA family of AI models often used through hosted APIs or local inference. TelemHQ can track Llama jobs when the run reports model and usage metadata.View glossary entrySource: Meta Llama docs, QwenQwenA family of open foundation models from Alibaba Cloud’s Qwen team, used for language, coding, and multimodal AI workflows.View glossary entrySource: Qwen model site, DeepSeekDeepSeekAn AI model provider with an API that supports OpenAI-compatible and Anthropic-compatible usage patterns for model calls.View glossary entrySource: DeepSeek API docs, KimiKimiAn AI assistant and model platform from Moonshot AI, with model APIs that can be monitored when jobs report model, token, and run metadata.View glossary entrySource: Kimi API Platform, and GLMGLMA family of large models from Z.ai, formerly known internationally through Zhipu AI, used for coding, agent, and general AI workflows.View glossary entrySource: Z.ai, RAG syncs, evals, agents, and traditional cron jobscron jobA scheduled task that runs automatically, often on a server. TelemHQ tracks cron jobs by receiving a ping after each run.View glossary entrySource: AWS EventBridge Scheduler docs that need more than "it ran."
The useful pattern is simple: send one POST after the run, include the payload fields that matter, and keep the history somewhere your future self or team can actually inspect.