May 25, 2026
How Teams Can Track AIAISoftware that performs tasks normally associated with human judgment, language understanding, or pattern matching. In TelemHQ, AI usually means jobs that call a model, agent, or coding tool.View glossary entrySource: Google Cloud Generative AI glossary Usage In One Place
The useful part is not surveillance. It is agreeing on a small set of fields so scattered AI work can be understood later.
Agree On The Fields First
Team AI usage tracking works best when the payloadpayloadThe structured data sent with a request. In TelemHQ, payloads should contain safe operational metadata, not prompts, completions, secrets, customer data, or private paths.View glossary entrySource: MDN API glossary is boring.
Every job does not need the same provider. Every person does not need the same tool. But the shared fields should mean the same thing across the team.
For example, a useful team payload might include:
providermodelprojectstatustotal_tokensinput_tokensoutput_tokenscached_input_tokensreasoning_tokenscost_usdlatency_msorduration_msitems_processeditems_failedgit_repogit_branchissue_id
The key field is often project.
If three teammates all send project: "billing-api", their separate jobs can still roll up into one view of billing-api activity. The project becomes the shared noun that connects local scripts, coding agentsagentAn AI application that uses a model, instructions, state, and tools to work toward a goal. Agents are useful to monitor because they can run for a while and make multiple tool calls.View glossary entrySource: Google Cloud Generative AI glossary, scheduled jobsscheduled jobA background task expected to run at predictable times. If it misses its expected window, TelemHQ can mark the tracker as failing.View glossary entrySource: AWS EventBridge Scheduler docs, and CICIContinuous integration is the practice of frequently merging code into a shared repository and automatically building or testing it.View glossary entrySource: GitHub Actions CI docs tasks.
That is more useful than forcing every workflow into the same integration.
If your team has not agreed on a shared payload shape yet, start with one payload format for OpenAI, Claude, Codex, and other AI jobs.
A Small Payload Example
Here is the kind of payload I would want from a team member's AI job:
{
"provider": "openai",
"model": "gpt-5.2-chat-latest",
"project": "billing-api",
"git_repo": "company/billing-api",
"git_branch": "issue-482-refactor-invoices",
"issue_id": "482",
"status": "success",
"total_tokens": 9060,
"cached_input_tokens": 3100,
"reasoning_tokens": 800,
"cost_usd": 0.42,
"items_processed": 128,
"items_failed": 0
}
That payload does not tell you what the prompt said. It does not include generated code. It does not expose customer data.
It says enough to answer the operational questions:
- what ran
- where it belongs
- how much modelmodelThe AI system that processes input and returns output. For monitoring, the model name helps explain which tool or provider produced a run and how its token usage should be priced.View glossary entrySource: Anthropic model docs work happened
- whether it finished cleanly
- whether it did useful work
- which branchbranchA line of development in Git. Tracking branch names helps connect AI coding usage or job cost to a specific task or change.View glossary entrySource: Git glossary or issue it came from
That is usually the level of detail a team needs first.
The Team View Should Answer Practical Questions
The reason to collect this metadatametadataData about a run rather than the private content of the run itself, such as model name, duration, branch, item counts, or token totals.View glossary entrySource: MDN API glossary is not to create a leaderboard of who used the most AI.
That kind of view can get weird quickly.
The better question is: where does the team need visibility?
For a manager or tech lead, a shared view should answer:
- Which projects are using the most tokenstokensThe pieces of text an AI model processes. Token counts are often used to measure usage and calculate model cost.View glossary entrySource: OpenAI token guide?
- Which projects are failing most often?
- Which jobs are getting slower?
- Which model/provider mix is common across the team?
- Which branch or issue created an unexpected costcostThe money associated with a run, often estimated from token usage and provider pricing. TelemHQ can store cost fields when your job sends them.View glossary entrySource: OpenAI token guide spike?
- Which old automation still runs after the person who built it moved on?
For a developer, the same data should answer a different set of questions:
- Did my job send the fields the team expects?
- Did this branch cost more than the previous branch?
- Did cached tokenscached tokensInput tokens that a provider can reuse from previous context. Cached tokens may be reported separately because they can affect cost and performance.View glossary entrySource: OpenAI token guide reduce the cost?
- Did the evalevalA test or scoring run used to judge whether an AI system behaved well enough. TelemHQ can track eval score, pass rate, failures, and regressions.View glossary entrySource: Google Cloud Generative AI glossary or quality score drop after a change?
- Did the job process fewer items than normal?
That is the line I would keep: make the work easier to explain, not the person easier to judge.
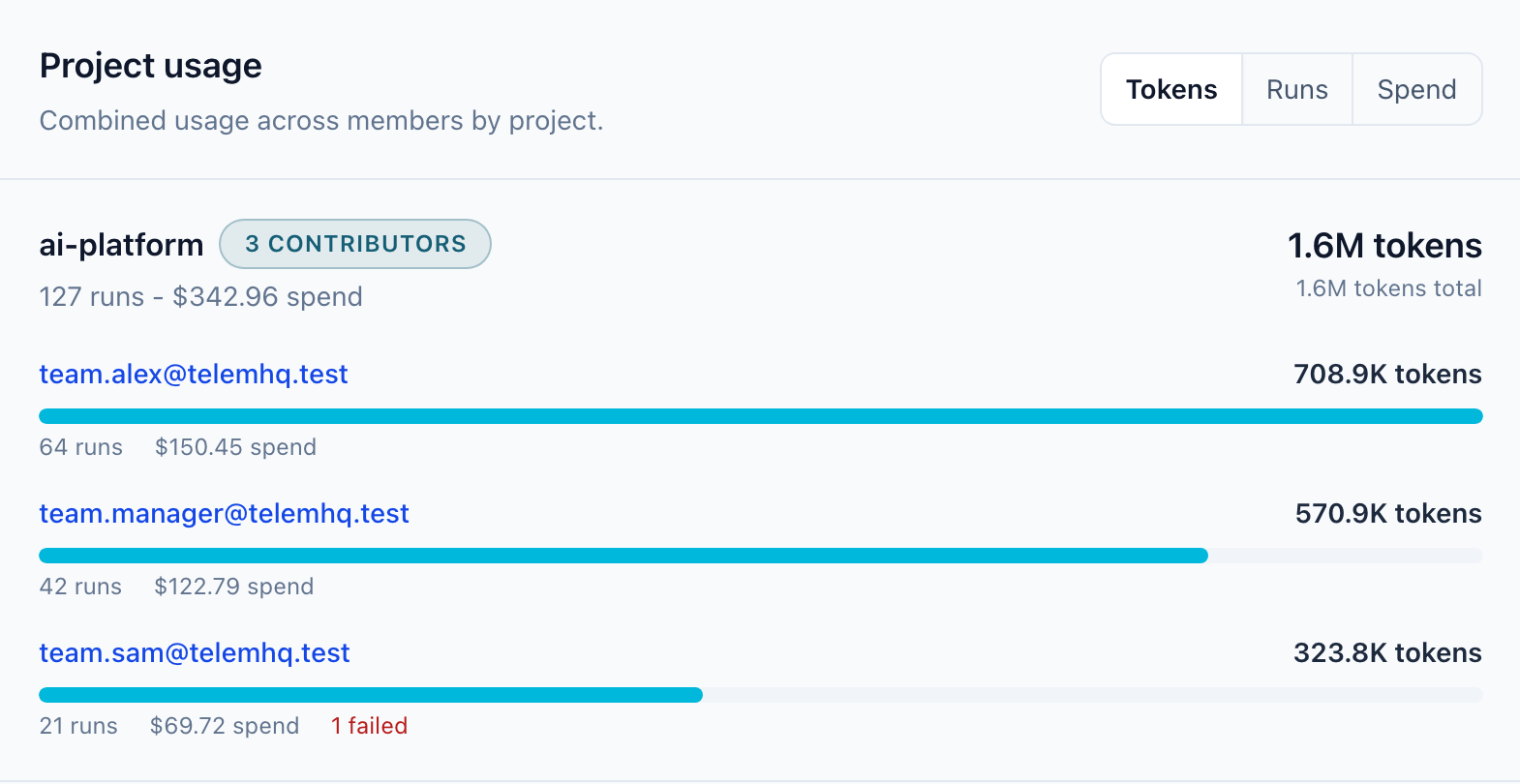
One Project Name Beats Three Dashboards
Imagine three people are working around the same service.
One person runs an AI coding tool while refactoring invoice logic:
{
"tool": "codex",
"provider": "openai",
"model": "gpt-5.3-codex",
"project": "billing-api",
"git_branch": "issue-482-refactor-invoices",
"total_tokens": 127200,
"cost_usd": 0.45,
"status": "completed"
}
Another person runs a ClaudeClaudeAnthropic’s family of AI models. TelemHQ can track Claude jobs by recording model names, token usage, latency, cost, and run metadata.View glossary entrySource: Anthropic model docs enrichment workerworkerA background process that performs work outside the main request path, such as syncing data, generating reports, or running AI tasks.View glossary entrySource: GitHub Actions CI docs:
{
"provider": "anthropic",
"model": "claude-3-5-haiku-20241022",
"project": "billing-api",
"status": "success",
"items_processed": 340,
"items_failed": 2,
"total_tokens": 18800,
"duration_ms": 42000,
"cost_usd": 0.08
}
A scheduled OpenAIOpenAIAn AI provider whose APIs and models are commonly used for text generation, coding, reasoning, embeddings, and agent workflows.View glossary entrySource: OpenAI token guide report runs every morning:
{
"provider": "openai",
"model": "gpt-5.2-chat-latest",
"project": "billing-api",
"status": "success",
"items_processed": 64,
"items_failed": 0,
"total_tokens": 12100,
"latency_ms": 3100,
"cost_usd": 0.04
}
Those jobs are different. The shared project value is what makes them comparable.
You can still drill into the details later, but the first pass is simple: billing-api used this many tokens, spent this much, ran these jobs, and had these failures.
Do Not Send The Whole Job
Team monitoring has a privacy problem if it collects too much.
For most AI jobs, metadata is enough.
I would not send:
- prompts
- completions
- generated code
- source files
- customer records
- secrets
- APIAPIA software interface that lets programs interact through defined rules, URLs, methods, and data formats.View glossary entrySource: MDN API glossary keys
- raw private paths
I would send:
projectprovidermodelstatus- token counts
- estimated cost
- latencylatencyHow long a request or job takes to respond. AI job latency helps teams spot slow model calls, overloaded workers, or expensive retries.View glossary entrySource: MDN glossary or duration
- item counts
- failure counts
- GitGitA distributed version control system used to track code changes. TelemHQ can store Git metadata like branch or issue identifiers with a run.View glossary entrySource: Git glossary metadata
- eval or quality scores
This matters more on a team because the audience is wider. A payload that feels harmless in a private script may become risky when it appears in a shared dashboard, an exported report, a webhookwebhookAn HTTP callback sent when an event happens. TelemHQ can use outgoing webhooks to notify another system about tracker events.View glossary entrySource: MDN API glossary, or a summary email.
Keep the shared historyrun historyThe stored record of previous job runs. TelemHQ uses run history to show payloads, failures, timing, token totals, and trends over time.View glossary entrySource: TelemHQ docs useful. Keep the sensitive work out of it.
Use AssertionsassertionA rule that checks payload data after a run. Assertions can flag a job as unhealthy even if the process technically completed.View glossary entrySource: TelemHQ docs For Bad Successful Runs
A successful process is not always a successful job.
An AI job can exit cleanly and still process zero items, exceed a cost budget, fail half its inputs, or return an eval score below the team's threshold.
That is where payload assertions help.
For a team AI job, I would start with rules like:
status = successitems_processed > 0items_failed = 0cost_usd <= 5eval_score >= 0.8
The exact rules depend on the job. The habit is the point.
If the team agrees on fields, the team can also agree on what a healthy run means.
Start Small
You do not need a full AI usage policy to start.
Start with one project and a small payload contract:
- Pick a shared
projectvalue. - Add
provider,model,status, and token fields. - Add
cost_usdwhen you can estimate it. - Add job-result fields such as
items_processed,items_failed, oreval_score. - Add Git fields when the work happens inside a codebase.
- Avoid prompts, completions, generated code, secrets, customer data, and raw private paths.
This is the part of TelemHQ I care about most for teams: not proving that someone used AI, but making the work legible enough that a team can debug it, budget it, and improve it.
If a team can agree on a few boring fields, the scattered usage starts to become a shared operational history.